엔터프라이즈 카프카 아키텍처 개요

엔터프라이즈 환경에서는 장애/복구, 성능 등을 위해 하나 이상의 데이터 센터를 사용하는 경우가 많다. 따라서 각 데이터 센터마다 카프카 클러스터를 배치해야 하고, 각 카프카 클러스터 간의 데이터 리플리케이션은 필수이다. 카프카 클러스터 안에서의 브로커 간의 리플리케이션이 아니라, 카프카 클러스터 간의 리플리케이션이다.
카프카 리플리케이션은 업스트림 카프카에서 다운스트림 카프카 사이에 필요할 수도 있고, 여러 카프카 데이터를 모으기 위해 필요할 수도 있다. 이렇게 복제된 미러 카프카는 최적의 위치에서 엘라스틱 서치, HBase 등에 연결되어 사용될 수 있다.
지금까지 배운 내용을 종합해서 위와 같은 엔터프라이즈 아키텍처를 만들고자 한다. 2개의 카프카 클러스터가 존재하고, 다운스트림 카프카는 업스트림 카프카를 미러링한다. 이때 카프카 리플리케이션을 위해서 미러메이커 2.0을 사용한다. 그리고 양쪽의 카프카 클러스터는 스키마관리를 위해 스키마 레지스트리를 사용한다.
엔터프라이즈 카프카 환경 구성
실습에는 위처럼 서버/애플리케이션을 구성할 것이다. kafka01~kafka03이 업스트림 카프카 클러스터이고, zk01~zk03이 다운스트림 카프카 클러스터이다.본래는 주키퍼 앙상블도 2개로 구성해야 하지만, 6개의 서버를 사용하여 실습하기 위해 하나의 주키퍼 앙상블을 두개의 카프카 클러스터가 바라보도록 하였다.
미러메이커는 카프카 다운스트림에 위치해 있는데, 이는 이유가 있다. 미러메이커는 1) 업스트림 카프카에서 메시지를 가져오고 2) 메시지를 다운스트림 카프카로 보낸다. 이렇게 2가지 동작으로 이루어진다. 만약 미러메이커가 업스트림에 위치해 있다고 하면, (1)의 동작은 내부 회선을 통해 이루어지고 (2)의 동작은 외부회선을 통해 이루어진다. 즉 업스트림에서 메시지를 가져오는 동작에는 큰위험이 없으나, 이 메시지를 다운스트림으로 보낼때 위험이 증가하여 메시지가 유실될 수 있다. 하지만 미러메이커가 다운스트림에 위치해 있으면 (1)의 동작은 외부 회선을 통하고 (2)의 동작은 내부 회선에서 이루어진다. 따라서 처음부터 업스트림의 메시지를 읽어오지 못할수는 있어서 메시지가 유실될 위험은 크지 않다.
엔터프라이즈용 카프카 운영 실습
> cd kafka2/
> cd chapter12/ansible_playbook
> ansible-playbook -i hosts site.yml
> ansible-playbook -i hosts expoter.yml
> ansible-playbook -i hosts monitoring.yml
CMAK을 이용한 토픽 생성
카프카 커텍트 설정
> curl http://kisu-zk01.foo.bar:8083/connectors
> curl --header "Content-Type: application/json" --header "Accept: application/json" --request PUT --data '{"name": "kisu-mirrormaker2","connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector","tasks.max": "1","source.cluster.alias": "src","target.cluster.alias": "dst","source.cluster.bootstrap.servers": "kisu-kafka01.foo.bar:9092,kisu-kafka02.foo.bar:9092,kisu-kafka03.foo.bar:9092","target.cluster.bootstrap.servers": "kisu-zk01.foo.bar:9092,kisu-zk02.foo.bar:9092,kisu-zk03.foo.bar:9092","replication.factor": "3","topics": "kisu-avro01-kafka1" }' http://kisu-zk01.foo.bar:8083/connectors/kisu-mirrormaker2/config
> curl http://kisu-zk01.foo.bar:8083/connectors/kisu-mirrormaker2/status | python -m json.tool
모니터링 환경 구성
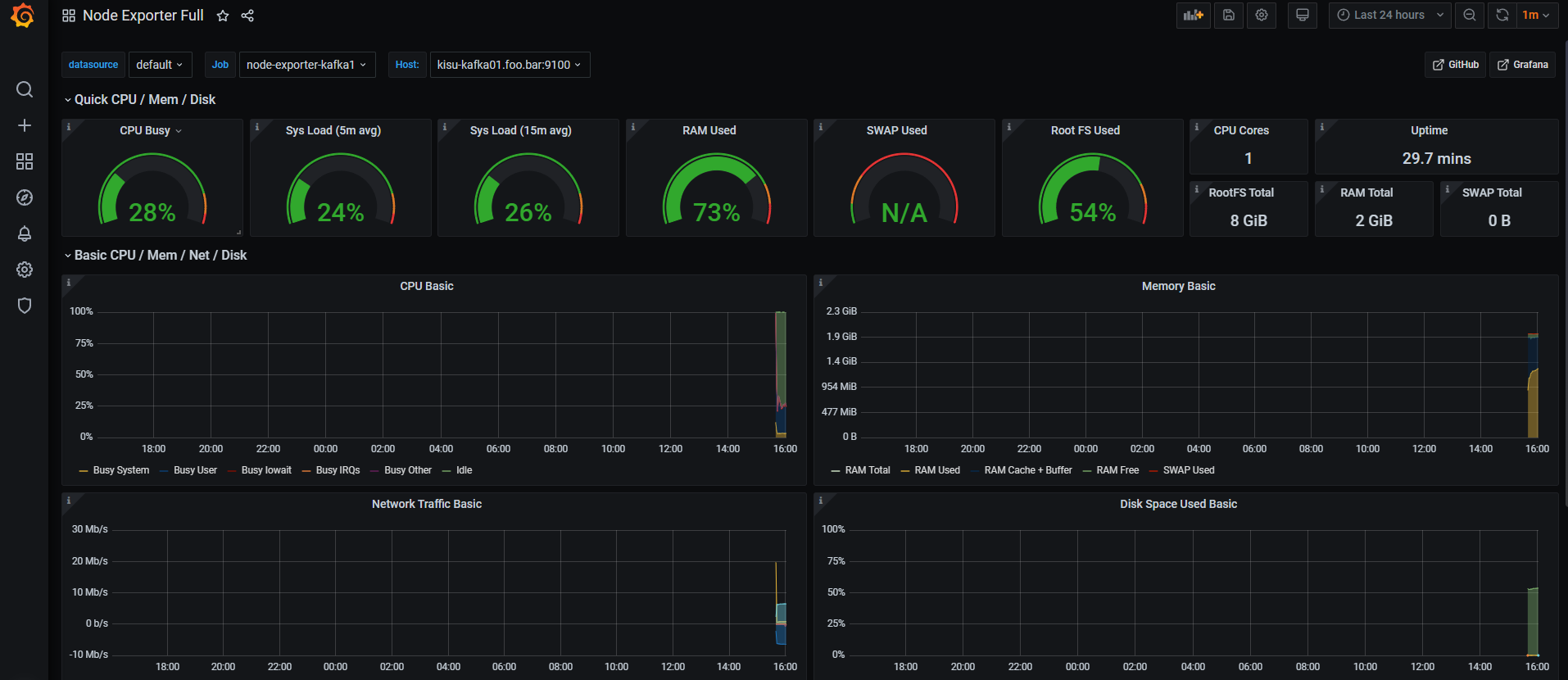
메시지 전송과 확인
> git clone https://github.com/onlybooks/kafka2.git
> sudo yum -y install python3
> python3 -m venv venv12
> source venv12/bin/activate
> pip install confluent-kafka[avro]
> pip install names
> pip install elasticsearch
> python kafka2/chapter12/python/producer-1_kafka-1_v1.py
> python kafka2/chapter12/python/consumer-1_kafka-1_v1.py
> python kafka2/chapter12/python/consumer_kafka-2_producer_es_v1.py

실습중 문제 해결
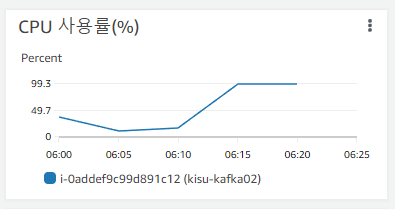
실습중 'start kibana container' task에서 앤서블 실행이 멈추고 진행이 안되는 현상이 발생하였다. 해당 task를 확인해보니 elasticsearch host에서 실행이 되고, hosts파일을 보면 elasticsearch는 kisu-kafka02.foo.bar 인스턴스가 포함되어있다. 혹시나 하는 마음에 해당 인스턴스의 상태를 보니, CPU 사용율이 99.9%까지 치솟아 있었다. 그래서 인스턴스의 CPU 사양이 문제라고 생각하였다 t2.small에서 t2.medium으로 인스턴스 유형을 변경하니 문제가 해결되었다.
https://aws.amazon.com/ko/blogs/big-data/best-practices-for-running-apache-kafka-on-aws/
'STUDY > 실전 카프카 개발부터 운영까지' 카테고리의 다른 글
| 5장 - 프로듀서의 내부동작 원리와 구현 (0) | 2022.05.31 |
|---|---|
| 3장 - 카프카 기본 개념과 구조 (0) | 2022.05.25 |
| 카프카 환경 구성, peter 대신 내 이름 쓰기 (0) | 2022.05.24 |
| 2장 - 카프카 환경 구성 (0) | 2022.04.26 |
| 1장 - 카프카 개요 (0) | 2022.04.19 |



