Server Side Rendering / Client Side Rendering
SSR(Server Side Rendering)이란 사용자에게 보여질 페이지가 서버에서 완성되어 전달되는 것을 말한다. 클라이언트(브라우저)는 그저 서버로 부터 받아온 정보를 사용자에게 그대로 보여주기만 하면 충분하다. SSR은 클라이언트의 성능에 크게 영향을 받지 않고, SEO 측면에서도 장점이 있다.
CSR(Client Side Rendering)은 사용자에게 보여질 페이지가 클라이언트(브라우저)에서 만들어지는 것을 말한다. 서버는 완성된 HTML 파일이 아니라, 이를 만드는데 필요한 스크립트 코드와 관련 정보들을 반환한다. 클라이언트는 이를 자체적으로 스크립트를 실행하여 비어있는 HTML 코드들을 완성시킨다. CSR은 효율적으로 데이터를 사용할 수 있고, 필요에 따른 부분적 렌더링 교체로 브라우저가 더욱 효율적으로 동작 할 수 있도록 해준다.
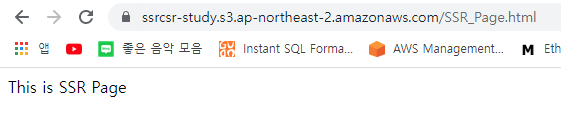

위 두개의 페이지는 사용자에게 보여지는 모습은 유사하다. 하지만 하나는 SSR 방식, 나머지 하나는 CSR 방식으로 만들어졌다.

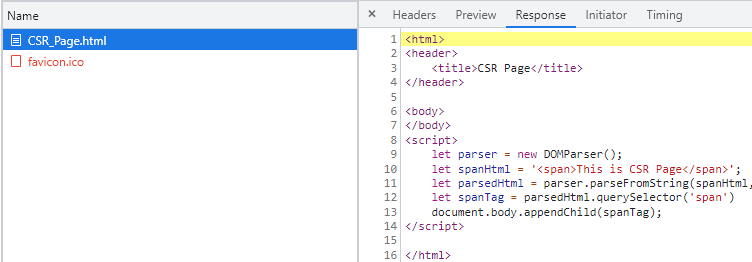
각각 서버에서 받아온 내용을 보면 SSR 방식은 온전한 Html이 반환되어, 클라이언트는 그대로 화면에 뿌려주는 역할만을 하였다. 반면 CSR의 경우, 비어있는 Html이 반환되어서 클라이언트가 스크립트를 실행하여 비로소 화면을 완성시킨다.
CSR 시대의 크롤링의 어려움
기존의 jQuery시대를 지나 Vue와 React로 웹 front의 대표 기술이 바뀌었다. 그리고 Vue와 React는 대부분 CSR, SPA(Single Page Application) 방식으로 동작한다. 그리고 이러한 변화는 웹페이지 크롤링을 어렵게 만들었다.
URI requstUrl = new URI("https://ssrcsr-study.s3.ap-northeast-2.amazonaws.com/SSR_Page.html");
HttpRequest request = HttpRequest.newBuilder(requstUrl).GET().build();
String response = HttpClient.newHttpClient().send(request, BodyHandlers.ofString()).body();
Document doc = Jsoup.parse(response);
Elements span = doc.select("span");
System.out.println(span); // <span>This is SSR Page</span>
URI requstUrl = new URI("https://ssrcsr-study.s3.ap-northeast-2.amazonaws.com/CSR_Page.html");
HttpRequest request = HttpRequest.newBuilder(requstUrl).GET().build();
String response = HttpClient.newHttpClient().send(request, BodyHandlers.ofString()).body();
Document doc = Jsoup.parse(response);
Elements span = doc.select("span");
System.out.println(span); // empty
위에서 본 SSR_Page와 CSR_Page의 span 태그를 크롤링하는 간단한 코드이다. SSR_Page의 경우 간단하게 span 태그를 찾아서 그 값을 보여주지만, CSR_Page의 경우 서버가 반환하는 내용에는 span 태그가 없기때문에 빈값을 반환한다. 이처럼 CSR 방식의 페이지를 크롤링하기 위해서는, 단순히 응답값을 분석하는 방식으로는 한계가 있다.

위에서 CSR 페이지를 크롤링하는데 실패한 이유는, 클라이언트가 페이지를 완성시키기 전 단계에서 크롤링을 시도했기 때문이다. CSR 방식의 경우, 렌더링이 완료된 이후(브라우저가 동작하고 난 이후)의 단계에서 크롤링을 시도해야한다. 그리고 이는 결국 브라우저 필요하다는 말이다.
Selenium을 활용한 Crawling
셀레니움(Selenium)이란 웹 응용 프로그램 테스트를 위한 휴대용 프레임 워크. 익스플로러, 크롬, 파이어 폭스 등 다양한 웹 브라우저로 웹사이트를 동작시키고 테스트 하기 위해 만들어진 도구이다. 하지만 브라우저를 자동으로 동작시키고 그 내용을 얻을 수 있다는 점에서 크롤링에도 사용되고 있다.

WebDriver driver = new ChromeDriver();
driver.get("https://ssrcsr-study.s3.ap-northeast-2.amazonaws.com/CSR_Page.html");
Document doc = Jsoup.parse(driver.getPageSource());
Elements span = doc.select("span");
System.out.println(span); // <span>This is CSR Page</span>
셀레니움을 사용해 CSR_Page를 크롤링 해보면, 이번에는 성공적으로 span 태그를 찾는 모습을 볼 수 있다. Selenium이 브라우저를 동작시켜서 서버로부터의 응답 값을 받아오고, 브라우져에 의해 렌더링된 결과값을 반환해주기 때문이다.
'STUDY > 기타' 카테고리의 다른 글
| Flyway를 활용한 DB Migration (0) | 2023.05.23 |
|---|---|
| Jest와 React (0) | 2023.02.21 |
| 교차 출처 리소스 공유 (CORS) : 개발자라면 한번은 보았던 것 (0) | 2022.02.15 |
| 채팅을 위한 노력의 역사 그리고 WebRTC (1) | 2021.12.02 |
| Java 8 ~ 11 버젼별 특징 (0) | 2021.11.01 |


