멀티모달 RAG

LLM은 최신 정보 답변 불가, 부정확한 답변, 정보 출처 불분명 등 여러 한계를 가지고 있다. RAG은 참고할 문서를 찾아서 사용자의 요청과 함께 LLM에 전달함으로써 한계를 해결한다. 그리고 이전까지 살펴본 RAG은 모두 텍스트만을 다루고 있었다. 사용자의 요청도 텍스트이고, 참고할 문서도 모두 텍스트이다. 하지만 멀티모달 RAG은 여기서 더 나아가 오디오, 이미지, 비디오 등 여러 양식의 데이터를 다룬다. 세상의 정보는 텍스트로만 이루어져 있지 않다. 오히려 텍스트 이외의 데이터가 더욱 많다. 그래서 텍스트 뿐 아니라 여러 데이터를 다루는 멀티모달 RAG이 다양한 정보를 함께 이해하고 더 풍부한 답을 줄수 있다.
멀티모달 RAG 구조

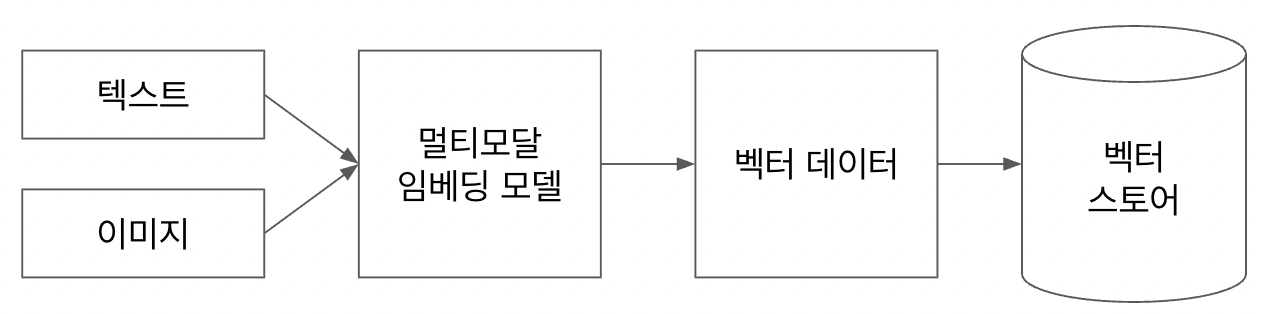
텍스트 데이터만 다룰때는 RAG의 구조가 단순했다. 텍스트 테이터를 텍스트 임베딩 모델을 사용하여 벡터 데이터로 바꾸고, 이를 벡터 스토어에 저장하였다. 그런데 이미지 데이터도 함께 다룬다면 어떻게 해야할까? 첫번째로 이미지를 다시 텍스트 데이터로 변환하여 활용하는 방법이 있다. 이미지를 텍스트 데이터로 변환하면 이후 과정은 기존 텍스트 데이터를 다룰때와 크게 다르지 않을 것이다. 다른 양식의 데이터도 같은 방식으로 다룰 수있다. 두번째로 데이터를 벡터로 변환할 때, 텍스트 임베딩 모델이아니라 멀티모달 임베딩 모델을 사용하는 것이다. 멀티모달 임베딩 모델이 지원하는 양식만 사용할 수 있다는 단점이 있다.
실습: 쇼핑몰 옷 추천 RAG

만약 쇼핑몰의 제품을 추천해주는 챗봇을 만든다면, 특히 의류 카테고리의 제품이라면 텍스트 데이터로는 한계가 있을것이다. 물론 의류 제품의 정보를 텍스트로 저장하고 이를 바탕으로 추천해주는 것도 가능하겠지만, 이미지를 활용한 챗봇이 더욱 사용자의 구매를 촉진할 수 있을것이다. 다음과 같은 제품 이미지를 가지고, 제품을 추천하는 RAG을 만들어보겠다.
import os
from PIL import Image # For image manipulation if handling b64_json
os.environ['OPENAI_API_KEY'] = ""
image_list = [Image.open("/image_path/" + file) for file in os.listdir("/image_path/") if 'png' in file]import base64
from io import BytesIO
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
def encode_image(image):
buffer = BytesIO()
image.save(buffer, format="PNG")
image_bytes = buffer.getvalue()
return base64.b64encode(image_bytes).decode('utf-8')
def image_summarize(image):
chat = ChatOpenAI(model="gpt-4o", max_tokens=1024)
prompt = """당신은 이미지를 요약하여 검색에 사용할 수 있도록 돕는 어시스턴트입니다.
이 요약은 임베딩되어 원본 이미지를 검색하는 데 사용됩니다.
이미지를 간결하게 요약하고 검색에 최적화된 내용을 작성하세요.
한국어로 작성하세요."""
img_base64 = encode_image(image)
msg = chat.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"},
},
]
)
]
)
return msg.contentimage_summary_list = [image_summarize(image) for image in image_list]
먼저 폴더에서 image_list로 이미지들을 불러왔다. 그리고 gpt-4o 모델을 사용하여 이미지를 텍스트로 변환하는 image_summarize 함수를 만들었다. image_summarize 함수를 호출하여 image_list에 있는 이미지들을 텍스트로 요약해서 image_summary_list에 저장하였다.
import uuid
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
def create_multi_vector_retriever(
vectorstore, image_summary_list, image_list
):
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
def add_documents(retriever, doc_summaries, doc_contents):
doc_ids = [str(uuid.uuid4()) for _ in doc_contents]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(doc_summaries)
]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, doc_contents)))
if image_summary_list:
add_documents(retriever, image_summary_list, image_list)
return retriever
vectorstore = Chroma(
collection_name="multimodal_rag", embedding_function= OpenAIEmbeddings(model="text-embedding-3-large")
)
retriever_multi_vector_img = create_multi_vector_retriever(
vectorstore,
image_summary_list,
image_list,
)from PIL import Image
from IPython.display import Image, display
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
def sendQueryWithImage(query):
chat = ChatOpenAI(model="gpt-4o")
prompt = f"당신은 쇼핑몰에 근무하는 유능한 종업원입니다. 주어진 제품 이미지를 바탕으로 고객의 요청에 적절한 답변을 제공하세요. \n고객의 요청: {query}"
image = retriever_multi_vector_img.invoke(query)[0]
img_base64 = encode_image(image)
msg = chat.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"},
},
]
)
]
)
display(image.resize((500, 500)))
print(msg.content)
그리고 벡터스토어를 만드는 create_multi_vector_retriever 함수를 선언하였다. 주목해야 할 것은 벡터 스토어뿐만 아니라, 원본 문서를 보관할 스토어까지 만든다는 것이다. 벡터스토어에서 사용자의 요청에 가장 가까운 이미지의 id를 찾아서, 원본 문서를 보관한 스토어에서 실제 이미지를 가져오는 방식이다. 그리고 실제 LLM에 요청을 보내는 sendQueryWithImage 함수까지 만들어서 실행을 해보면, 이미지를 바탕으로 답변을 하는것을 볼 수 있다.
'STUDY > 실전 RAG 기반 생성형 AI 개발' 카테고리의 다른 글
| LLM 비용 최적화: 토큰, 캐싱, 그리고 파인튜닝 (0) | 2025.09.29 |
|---|---|
| 3. RAG 검색 성능 개선 (2) | 2025.05.30 |
| 2. 임베딩과 벡터저장소를 활용한 RAG (2) | 2025.05.27 |
| 1. LLM의 한계와 RAG(검색 증강 생성) (6) | 2025.05.21 |


